💡 RDBMS와 NOSQL 비교
RDBMS
- 데이터의 관계를 Foreign Key 등으로 정의하고 이를 이용해 Join 등의 관계형 연산을 함
- 하나의 고성능 머신에 데이터 저장 (수직적 확장)
- 테이블 스키마 변경 불가
- 대부분의 데이터베이스에서 안정적으로 사용 가능
NOSQL
- 데이터 간의 관계를 정의하지 않음
- 일반적인 서버 수십 대를 연결해 데이터를 저장 및 처리하는 구조 (수평적 확장)
- 테이블 스키마 유동적
- 대용량 데이터 처리에 좋음
CAP 이론
분산 컴퓨팅 환경은 Consistency(일관성), Availability(가용성), Partitioning(부분결함 용인) 3가지 특징을 가지고 있으며, 이 중 2가지만 만족할 수 있다는 이론
(ps. 시간이 지나면서 CAP 이론의 부족한 부분을 보완하기 위해 PACELC 이론이 나왔다.)
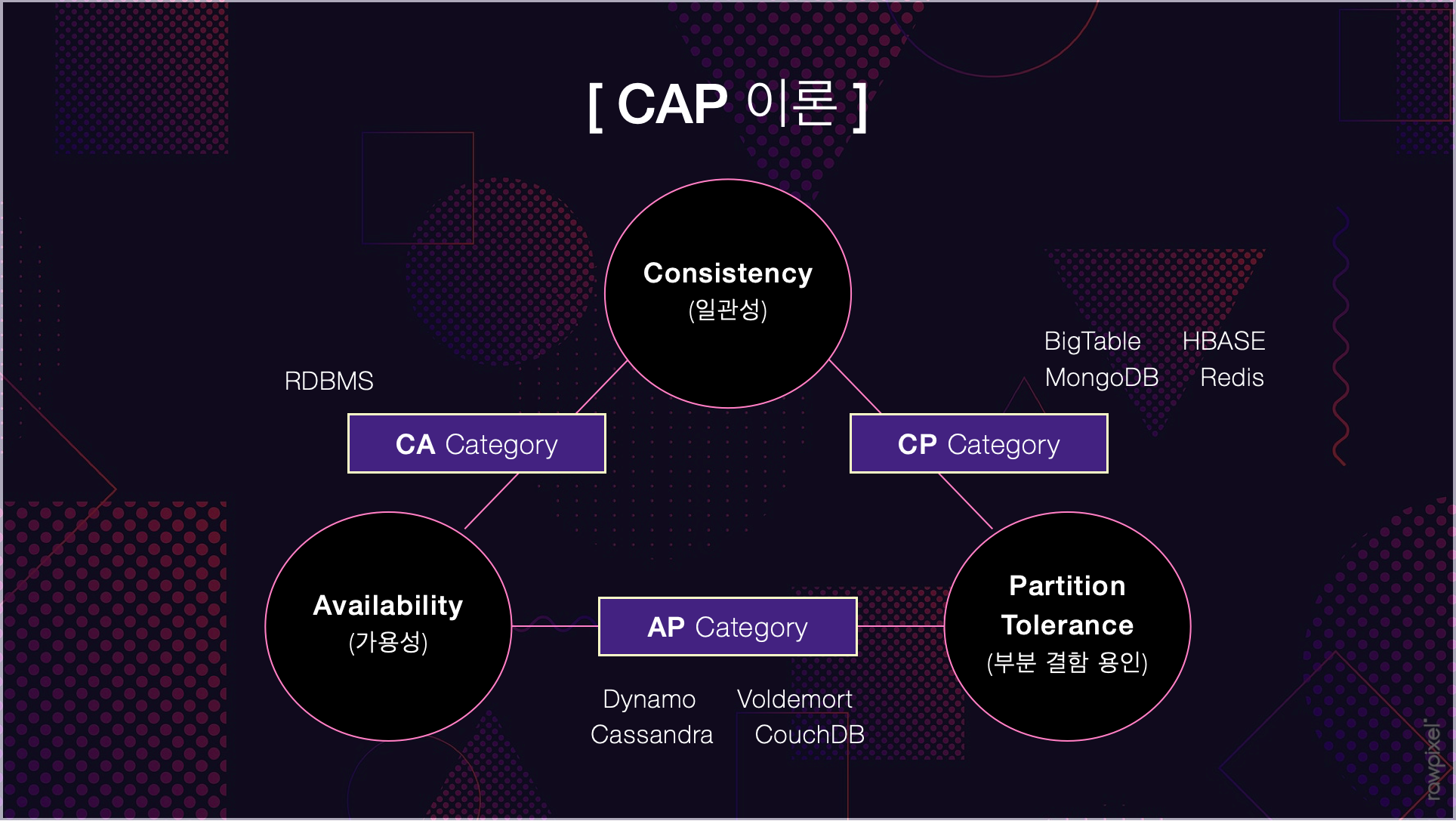
RDBMS는 CA Category에 속하므로 부분 결함을 용인하지 않기 때문에 일관성과 가용성에 포커스를 두고 지킬 수 있다.
NoSQL은 CP Category(일관성 - 부분 결함 용인), AP Category(가용성 - 부분 결함 용인) 두 가지 경우가 있는데, 두 가지 모두 부분결함을 용인한다. 따라서 불가피하게 데이터가 유실될 수 있는 가능성을 가지고 있지만 그렇기 때문에 시스템 확장이 용이하고 신속하게 빅데이터를 처리할 수 있는 장점을 가진다.
RDBMS
Relational DataBase Management System으로 관계형 데이터베이스 관리 시스템을 뜻한다. 관계형 데이터 모델은 데이터 간의 상관관계에서 개체간의 관계를 2차원의 테이블 형태로 표현한다. 역사가 오래되어 가장 신뢰성이 높고 가장 많이 사용되어져 왔다.
탄생 배경
기존 컴퓨팅 시스템은 기업 업무를 자동화하고 효율화하는 데에 목적이 있었다. 기업의 복잡한 데이터를 저장하고 그 데이터 간의 관계를 정의하고 분석하는 데에 최적화된 RDBMS가 만들어졌다. 기업의 업무 시스템은 해당 기업의 생산과 판매를 지원하기 위한 것이었고, 생성되는 데이터양은 한계를 가지고 있었다.
특징
한 테이블에 있는 모든 로우는 같은 길이의 칼럼을 가지고 있으며 이 칼럼의 구조와 데이터의 관계가 테이블 스키마(Schema)로 사전 정의된다. 분류, 정렬, 탐색 속도가 빠르다. SQL은 고도로 정교한 검색 쿼리를 제공하며 상상하는 거의 모든 방식으로 데이터를 다룰 수 있게 해 준다. 또한 트랜잭션(Transaction) 지원이 매우 강력하여 신경만 제대로 써주면 데이터가 안 들어가는 경우는 있어도 잘못 들어가는 경우는 없다. 그 어떤 상황에서도 데이터 무결성을 '보장'하는 것이 RDBMS의 특징이다.
다만 부하분산이 잘 되지 않는다. 읽기 작업은 분산이 되지만 쓰기 작업을 분산하려면 고도의 기술력에 더해 전략까지 필요하다.
장점
- 범용적이며 고성능
- 데이터의 일관성을 보증할 수 있음
- 한 번에 이뤄져야 하는 작업의 경우 데이터 불일치 상황 방지 (데이터 무결성 보장) → 데이터베이스 설계 시 이미 불필요한 중복이 삭제됨
- 정규화를 전제로 하고 있기 때문에 업데이트 시 비용이 적음(동일 컬럼은 동일 장소에 존재)
- 복잡한 형태의 쿼리도 가능(Join 등)
단점
- 대량의 데이터 입력 처리 어려움
- 테이블의 인덱스 생성이나 스키마 변경 어려움
스키마(Schema) : 데이터 구조와 데이터 타입, 관계 등을 정의한 세부 명세
트랜잭션(Transaction) : 복수의 쿼리를 한 단위로 묶은 것
어떤 상황에 사용할까?
대부분의 경우에 관계형 데이터베이스를 사용하는 것이 안정적이다.
- 관계를 맺고 있는 데이터가 자주 변경(수정)되는 어플리케이션일 경우
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
모델링 과정
관계형 데이터 모델링은 전형적으로 가용한 데이터 구조에 기반한다.
데이터 모델 정의 후, 어플리케이션에 맞는 쿼리를 개발한다.
- 저장하고자 하는 도메인 모델 분석
- 개체 간의 관계(relationship) 식별
- 테이블 추출
- 테이블을 이용한 쿼리 구현
NOSQL
NoSQL은 Not Only SQL의 약자로 기존 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미한다. RDBMS를 NoSQL을 대체하는 것이 아닌, 기존 RDBMS의 단점을 보완해주는 형태라고 할 수 있다.
탄생 배경
2000년대에 들어서면서 인터넷의 발전과 함께 SNS 서비스가 활성화 되고, SNS 서비스 시스템은 전세계 사용자 대상의 서비스로 발전하였다. 기존의 기업 시스템에서 볼 수 없었던 대규모 데이터를 생산되었고 이러한 데이터들은 기존 기업 데이터에 비해 매우 단순한 형태를 가진다.
데이터의 패러다임이 한정된 규모의 복잡성이 높은 데이터에서 단순한 대량의 데이터로 넘어가기 시작했다. 기존의 데이터 저장 시스템으로는 커버할 수 없는 여러 가지 한계를 야기했고 결국에는 새로운 형태의 데이터 저장 기술을 요구하게 되면서 NOSQL이 탄생하게 되었다.
특징
NoSQL이라고 해서 RDBMS 제품군(MS-SQL, Oracle, Sybase, MySQL) 등과 같이 공통된 형태의 데이터 저장 방식(테이블)과 접근 방식(SQL)을 갖는 제품군이 아니라 RDBMS와 다른 형태의 데이터 저장 구조를 총칭하며, 제품에 따라 각기 그 특성이 매우 달라서 NoSQL을 하나의 제품군으로 정의할 수는 없다.
RDBMS의 복잡도와 용량 한계를 극복하기 위한 목적으로 등장한 만큼, 페타바이트급의 대용량 데이터를 저장할 수 있다. 기본적으로 NoSQL의 join연산은 대부분 불가능하다. 즉, 데이터 모델 자체가 독립적으로 설계되어 있어 데이터를 여러 서버에 분산시키는 것이 용이하다. 분산형 구조를 통해 데이터를 여러 대의 서버에 분산해 저장하고, 분산 시에 데이터를 상호 복제해 특정 서버에 장애가 발생했을 때에도 데이터 유실이나 서비스 중지가 없는 형태이다. ID 필드는 공통이지만, 데이터를 저장하는 컬럼은 각기 다른 이름과 다른 데이터 타입을 가질 수 있다.
장점
- 특정용도로 특화되어 있음
- 데이터 분산에 용이
- 유연한 데이터 모델
- 수평적 확장
- 빠른 쿼리
단점
- 각 솔루션의 특징을 이해할 필요가 있음
- 버그가 상대적으로 많이 있음
- 데이터 중복으로 인한 수정 작업의 번거로움
어떤 상황에 사용할까?
- 데이터에 대한 캐시가 필요한 경우
- 배열 형식의 데이터를 고속으로 처리할 필요가 있는 경우
- 어쨌든 모든 데이터를 저장하고 싶은 경우 (막대한 양의 데이터를 다뤄야하는 경우)
- 읽기 처리를 자주하지만, 데이터를 자주 변경하지 않는 경우
데이터 모델링 과정
어플리케이션의 특징적인 데이터 접근 패턴에 따라 모델링한다.
어플리케이션의 필요한 쿼리와 성능을 정의한 이후, 요구 사항에 부합하도록 데이터 모델을 구성한다.
- 도메인 모델 분석
- 쿼리 결과 도출
- 테이블(데이터 저장 모델) 설계
⍞ Reference
'Database' 카테고리의 다른 글
| [MySQL] 성능 튜닝 - 버퍼 풀 (0) | 2020.09.05 |
|---|---|
| [MySQL] 스토리지 엔진 - InnoDB, MyISAM (2) | 2020.09.04 |


댓글