🛷 2020년 3월 31일 진행된 "Cloud onBoard Online"을 정리하였습니다.
기본 개념
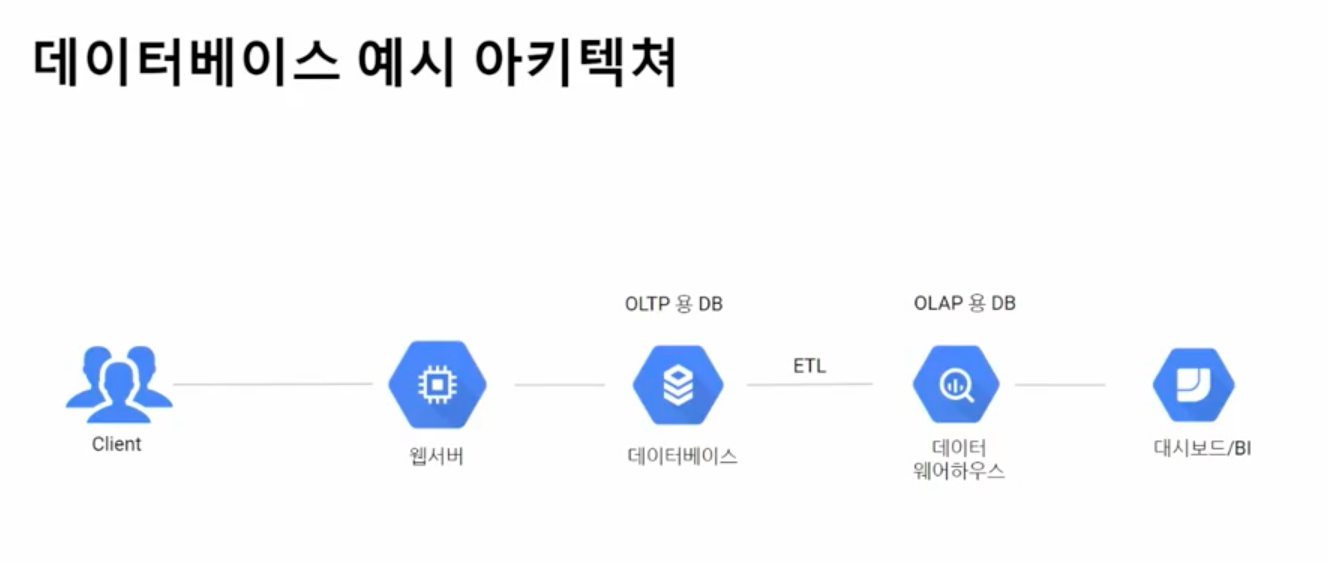
ex. 티켓 판매 온라인 사이트
- 저장 : 구매한 티켓 정보(누가 언제, 어떤 티켓을 구매했는지) 등
- 저장하는 곳 → DB(구체적으로는 Transactional DataBase (OLTP))
- 분석
DB에서 바로 분석가능 하지만
- 데이터를 건드릴 수 있는 위험부담이 있기 때문에
- 원천 데이터는 누락데이터나 Null값 등 가공되어있지 않기 때문에 정제할 필요가 있음
- 데이터 정제 → ETL(Extract - Transform - Load)
→ 분석용 DB(Analytical DB (OLAP)) 에 저장
- 데이터 정제 → ETL(Extract - Transform - Load)
- 레포팅/대시보드
스토리지 가이드라인
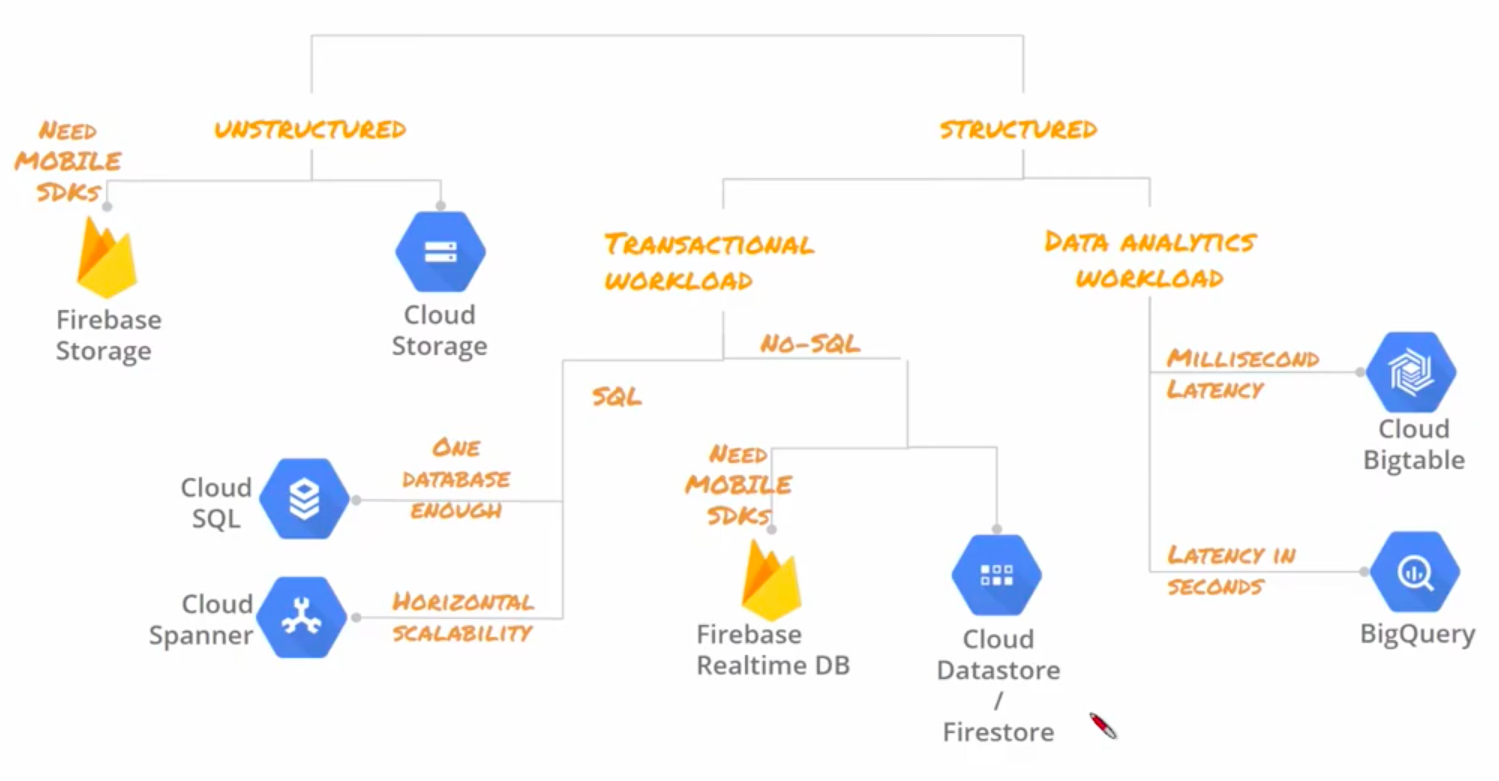
- Unstructured? Structured?
- 비정형 데이터가 있으면? → Cloud Storage
ex. 이미지, 오디오, 텍스트, 비디오 등
- 정형 데이터?
ex. 표 등
→ 데이터베이스에 따라 2번으로
- 비정형 데이터가 있으면? → Cloud Storage
- Transational? Analytical?
- OLTP?
→ 데이터 형태에 따라 3번으로
- OLAP?
- RDB? or (Latency는 조금 생기더라도) 복잡한 분석을 하고 싶어?→ BigQuery가 좀 더 적절
- key-value? or 데이터 엄청많다? 굉~~장히 큰 데이터다? → Bigtable가 좀 더 적절
- 낮은 Latency로 처리
ex. IoT 데이터, Time-series(시계열) 데이터
- OLTP?
- SQL? NoSQL?
- 관계형 DB냐? 즉, 행과 열로 되어있느냐? → Cloud SQL
- 용량이 겁나 많이 필요하다? → Cloud Spanner
- key-value? → Cloud Datastore(Ver.1), Firestore(Ver.2)
- 관계형 DB냐? 즉, 행과 열로 되어있느냐? → Cloud SQL
- DATA Lake가 필요해! → Cloud Stoarge
🤖데이터 크기, 상태에 따라
Data Lake(대량. 데이터 정제x) > Data Warehouse(정돈. ETL거침) > Data Mart(필요한 것만 뽑아 정리)
그렇다면,
Q. Data Warehouse는 어떤 스토리지를 사용하는게 적절할까?
A. BigQuery
Q. Data Mart는 어떤 스토리지를 사용하는게 적절할까?
A. BigQuery - Data Set
Cloud Stoage
BLOB(Binary Large-Object) ; 엄청나게 큰 저장공간으로 생각.
→ file 형태로 데이터가 있다면 사용
- 기본적으로 Google에서 엔드포인트로 전송 중인 데이터 암호화
- 용량을 관리할 필요가 없음
- 버킷으로 구성
- 고유한 이름 사용
- 오브젝트 버전관리 가능
- 오브젝트 수명 주기 설정 가능
- 엑세스 빈도에 따른 등급 선택 - 월별 요금 할인
- 권한제어
- 데이터를 가져오는 방법
- Online Transfer : 명령줄, 드래그 앤 드롭 방식
- Storage Transfer Service(추천) : 병렬로 데이터를 복사, 중단 후 재시작 시에도 이어서 가능
- Transfer Appliance : 물리적으로 데이터 이동(장비 보내주면 거기에 담아서 다시 보내면 됨)
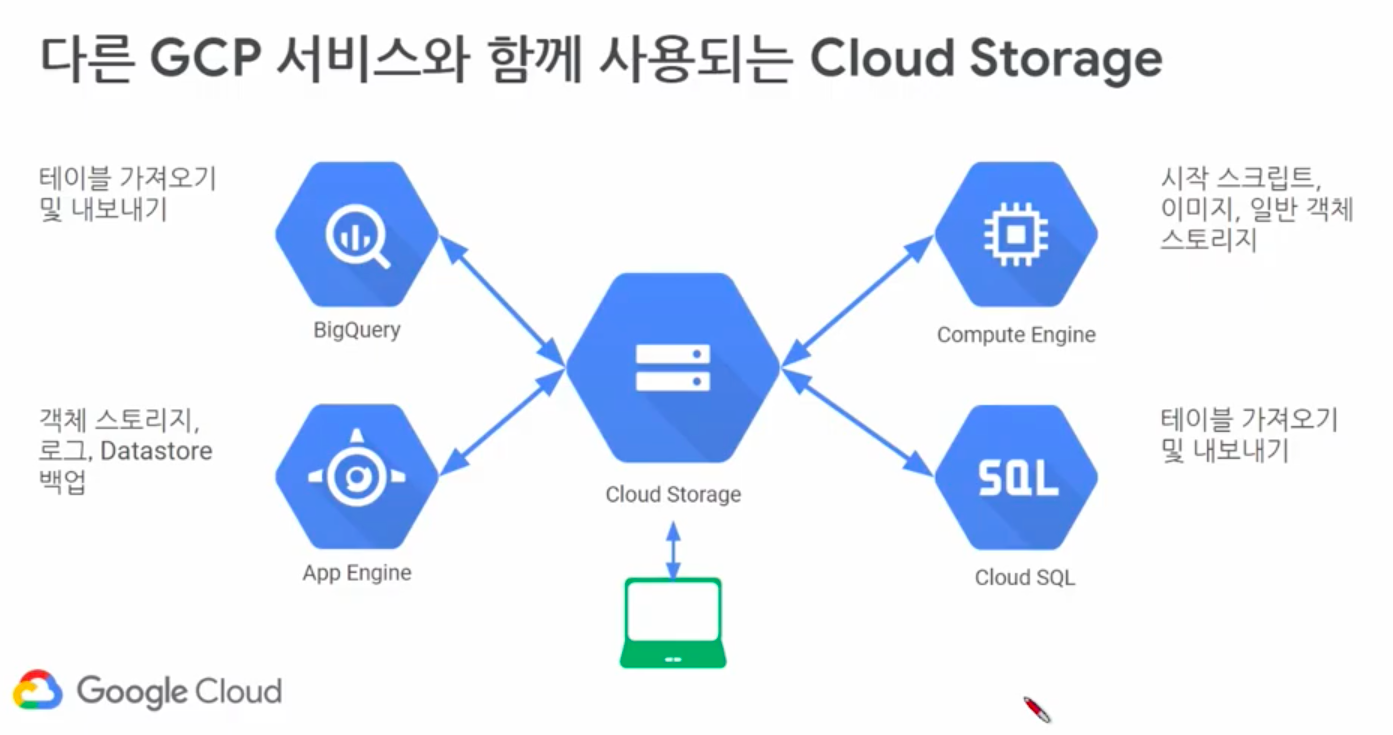
- 여러 제품과 함께 사용
Cloud BigTable
분석용 DB, 대용량 데이터, NoSQL
- 빅데이터, Hadoop 에코시스템과 기본적으로 호환
- 액세스 패턴 (ex. IOT, 머신러닝)
- Application API
- Streaming (실시간)
- Batch Processing (일괄 처리)
- 복제 스토리지
- 암호화
- 성능
Bigtable 노드가 많기 때문에 성능이 좋음!

- 사용자 요청 (데이터 읽고싶어!) - Node를 거쳐서 데이터 저장된 곳으로 감
Node는 Meta data를 가지고 있어 어디로 가야할지 포인팅 해줌 → 많으면 많을 수록 성능이 좋아진다.
🤫Q. 그러면 Transactional DB로 사용하면 안됩니까?
A. 적절하지 않음.
→ Strong Consistency가 아닌 Eventual Consistency를 보장하기 때문
* Transactional DB는 Strong Consistency를 보장해야함!
→ Cloud Storage, Cloud SQL, Cloud Spanner사용🤖Consistency?
분산시켜 데이터를 저장하면서 각각 DB에 업데이트를 해주는 그 속도에 따라,
- Strong Consistency : 한 DB에 업데이트가 일어나면 그 업데이트를 거의 동시에 모든 곳에서 업데이트가 가능하다면 (→ Cloud Storage)
- Eventual Consistency : 그러지 못할 경우, 바로바로는 아니더라도 궁극적으로 업데이트를 해준다 consistency를 보장해준다. (→ Eventual Storage) - 사용자 요청 (데이터 읽고싶어!) - Node를 거쳐서 데이터 저장된 곳으로 감
Cloud SQL 및 Cloud Spanner
Transactional DB. 관리형 RDBMS
- 자동 복제
- 관리형 백업
- 여러 제품과 같이 사용

- 전 세계적으로 사용? → Cloud Spanner 사용
- 강력한 Strong Consistency를 보장함! (External Consistency)
Cloud Datastore
Transactional, NoSQL
- 확장이 자유로움
- 스키마 없는 액세스 : 기본 데이터 구조를 고려할 필요 없음
스토리지 옵션 비교


클라우드 컨테이너

→ 서버자원, Network, 전력 등을 빌려주는 것
PaaS(Platform as a Service)
→ 인프라는 신경 쓰지 않고, 서비스를 개발 할 수 있는 안정적인 환경(Platform)과 그 환경을 이용하는 응용 프로그램을 개발 할 수 있는 API까지 제공하는 형태 (코드만 주면 됨)
컨테이너란?
- 각각의 서버에 애플리케이션 빌드

- 어플리케이션 - 커널 사이에 라이브러리 존재
→ Dependency(dll 등) 운영체제와 어플리케이션 사이에 커뮤니케이션을 도와줌
→ 유틸리제이션이 너무 낮았음
→ 증가시키기 위해 가상화시킴
- 어플리케이션 - 커널 사이에 라이브러리 존재
- 하나의 하드웨어 위에 (커널-디펜던시-어플리케이션)VM을 만듦

- 하나의 운영체제(Dependency)를 사용하여 어플리케이션을 여러개 돌리다보니 서로 영향을 너무 많이 받음
- 종속성 간의 문제
- 버전 관리의 어려움
- 운영체제를 두개 돌리자니 너무 무거워짐.
→ 두 방법 모두 문제가 큼 → 그래서 컨테이너 모델이 등장!
- 하나의 운영체제(Dependency)를 사용하여 어플리케이션을 여러개 돌리다보니 서로 영향을 너무 많이 받음
- 컨테이너 모델
하드웨어 - 운영체제1 - (Dependecy+Application)Container

- 어플리케이션끼리 독립적
- 운영체제에 대해 독립적
- 매주 평균 40억개의 새로운 컨테이너 생성
- 관리가 까다로움
→ 컨테이너들을 관리해 주는 친구? → 쿠버네티스
쿠버네티스
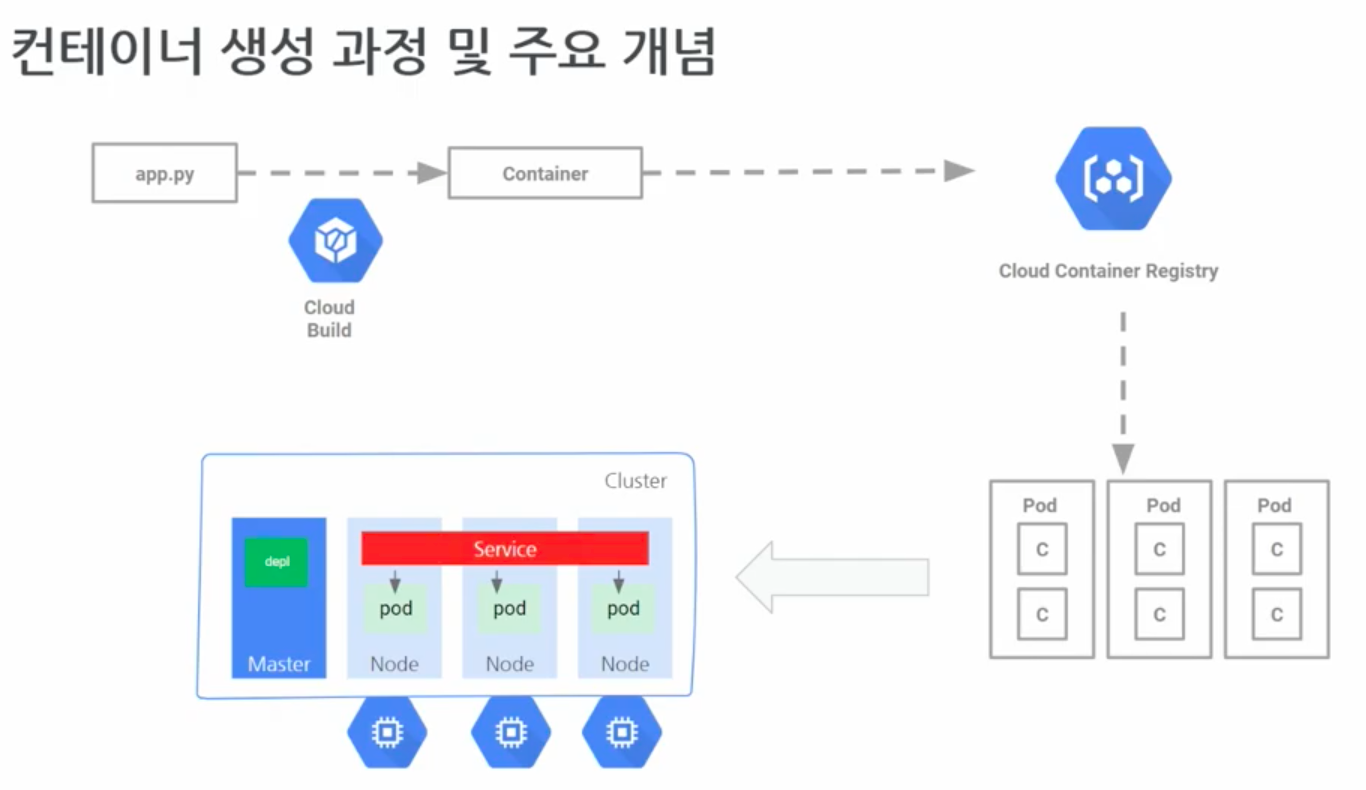
- 앱 개발
- 컨테이너로 변환
- Cloud Build, 도커 등으로 컨테이너로 만듦
- 개발 한 것을 공유
- Container Registry ; 컨테이너 보관 창고
깃헙과 같은 저장소(사설 깃) → 다른 사람들이 컨테이너를 사용하고 싶을 때 여기에서 가져옴
→ 이 때, 파드들을 생성하게됨
- Container Registry ; 컨테이너 보관 창고
- 파드 형성
- 컨테이너를 2~3개씩 묶어서 가져 옴
🤖파드란?
쿠버네티스 애플리케이션의 기본 실행 단위. 컨테이너의 묶음(단일 컨테이너 / 다중 컨테이너)
ex. 나중에 파드들끼리(즉, 컨테이너들 끼리) 의사소통을 해야하는 경우
의사소통을 하려면 인증, 혹은 관리를 해야하는데 바로 커뮤니케이션을 하지 않고 proxy를 통해서 커뮤니케이션
→ 프록시만 또 따로 파드로 만들어 사용→ 각각의 파드를 VM에 올려놓게 됨
- 쿠버네티스 사용
- 마스터
- 노드 : 파드가 배치가 되는 장소
관련 다양한 제품
- Kubernetes : 오픈소스
- Google Kubernetes Engine : GCP 제품
- 마스터 관리 해주는 제품
- Istio : 오픈소스
- 보안 인증 과정 담당
→ 파드 안 컨테이너끼리 의사소통을 할 때 서로 신뢰하지 않기 때문에 보안 인증의 과정이 필요하기 때문
- 보안 인증 과정 담당
- Anthos
- 하이브리드 시스템에서 사용
→ GCP와 온프레임을 같이 관리하는데 도움을 주는 제품
- 하이브리드 시스템에서 사용
Cloud Functions
아주 간단한 함수 작업을 할 때, 일일이 서버 구축을 할 필요 없이 사용 가능
- Node.js 환경에서 실행
Deployment Manager
인프라 관리 서비스
- .yaml 파일로 환경을 설명하는 템플릿을 만들고, Deployment Manager를 사용하여 리소스 생성
- 반복 가능한 배포 제공
Stackdriver

'Cloud' 카테고리의 다른 글
| [Cloud onBoard Online] 빅데이터, 머신러닝 (2) | 2020.05.14 |
|---|---|
| [Cloud onBoard Online] 가상 머신 (0) | 2020.05.13 |
| [Cloud onBoard Online] GCP 소개 (0) | 2020.05.12 |



댓글